In the first part of this series on Nvidia’s role in AI, we covered how the Artificial Intelligence (AI) arms race began. We examined the Graphic Processing Unit (GPU) requirements for training AI Models such as ChatGPT and Stable Diffusion. We saw that training AI Models is clearly expensive – it took 4,000 & 10,000 Nvidia A100 GPUs to train Stable Diffusion and ChatGPT.
Running AI Models is also extremely compute intensive. Currently Nvidia is the only game in town and the market realizes this. This is reflected in the PE ration of 137!
There is justifiable hype around AI. How much of this translates to higher revenues for Nvidia? How sustainable are these revenues and is Nvidia’s high valuation justified?
To answer these questions, we will look at:
- uses of Nvidia’s A100 and H100 chips
- signs of increased demand for AI Models &
- the competition in the start-up space and are they breathing down Nvidia’s neck?
Training vs Inference
AI Models are first trained on data sets to recognize patterns. Inference is the process where a pre-trained AI Model comes up with solutions/responses based on inputs or queries. Essentially ChatGPT writing a Haiku or Stable Diffusion drawing a unicorn in the style of Salvador Dali.
Drawing these Inferences takes a lot of processing power. GPU-based solutions offered by Nvidia are the most effective option for Training AI Models and Inference. A McKinsey study estimated the Data Center AI chip market at around $13 – 15 billion by 2025. Within the study is an interesting heuristic – 1/3rd of this market will be Training and 2/3rds will be Inference.
We can make an assumption that the need for Inference chips will be twice the demand for Training chips.
Inference at Data Centers vs the Edge
While Training AI Models happens exclusively at the Data Center, Inference can happen at 2 places; the Data Center and the Edge. Inference at the Edge refer to AI systems/models embedded in devices such as self-driving cars and high-end smartphones.
Nvidia dominates the Training AI Models market and Inference at Data Centers market with 90-95% of the market share. Inference at the Edge is a much more fragmented market. As most of the heavy lifting is done by the AI model at the Edge device, Inference at the Edge is computationally less demanding. Most of it is done by CPUs (Central Processing Units) or ASICs (Application-Specific Integrated Circuits). These chips are usually based on ARM design.
Autonomous Vehicles or Full Self Driving is one of the few instances of Inference at the Edge that requires GPUs. As you can expect, Nvidia is a strong contender in this market with its Nvidia DRIVE solution. The Drive platform made waves when Mercedes was the first to be approved for Level 3 driving in both US (Nevada) and Germany.
In short, most AI activity in Data Centers (whether Training or Inference) needs Nvidia GPU-based solutions.
A100 makes way for H100
A100 was Nvidia’s most sought after GPU till last year. It is described as the ‘workhorse’ of Artificial Intelligence. ChatGPT and Stable Diffusion were trained on the A100-based system – the DGX A100.
Eight A100 chips form the heart of the DGX A100. The components of the DGX A100 system include:
- 8x NVIDIA A100 GPUs
- 6x NVIDIA NVSwitches
- 10X NVIDIA Connectx
- AMD CPUs and 2 TB System Memory
- Gen4 NVME SSD
Nvidia AI solutions are scalable and DGX A100 is no exception. 20 DGXs can be combined to form a SuperPod. You can keep combining SuperPods to achieve Super Computer levels of compute.
A single DGX A100 system costs around $200,000 but of late the prices have dropped.
The Old makes way for the New – Enter H100
Complacency is not a word found in Nvidia’s dictionary. In May 2020, Nvidia had launched the A100. In Oct 2020, A100 aced the ML Perf benchmarks – the Industry standard for determining who has the fastest Inference solution.
In September 2022, Nvidia announced at GTC 2022 the launch of Nvidia H100 Tensor Core GPU. This demonstrated why Nvidia is so hard to beat in the GPU game – it is always innovating.
H100 predictably began dominating the ML Perf benchmarks shortly. It is said to be ‘an order of magnitude’ faster than A100. Predictably, companies began lining up and the order book exploded.
“In just the second quarter of its ramp, H100 revenue was already much higher than that of A100, which declined sequentially. This is a testament of the exceptional performance on the H100, which is as much as 9x faster than the A100 for training and up 30x cluster in inferencing of transformer-based large language models”
Colette Kress — Executive Vice President, Chief Financial Officer, Nvidia (NVDA) Q4 2023 Earnings Call, 22 Feb 2023
H100 is 3.5x expensive but 9-30x faster
The introduction of the H100 cetris paribus would have been revenue negative for Nvidia as compared to A100. The H100 has been reportedly selling at $36,000 – that’s 3.6 times the price of A100. We know that for Training, H100 is 4-9x faster than A100. For inferencing, it is up to 30X faster!
“30x cluster in inferencing of transformer-based large language models” Nvidia CFO Colette Kress.
This could mean that replacing A100s with H100s could be cheaper by 14% for Training and as much as 757% cheaper for Inference.
The H100s can also be combined like A100s to form a DGX solution. Interestingly, the H100-based DGX systems also seem to be priced similarly to A100 based DGX solution – around $200,000. Details on pricing are not available online so I would request you to take this with a pinch of salt.
If AI demand was static, this would have been bad news for Nvidia. The buzz around AI seems to indicate that the demand for AI will increase exponentially in the upcoming years.
Signs that AI Demand will Shoot through the Roof
Right from the Horses’ mouth – Nvidia
Jensen Huang confirmed in Q4 FY22 that demand for AI solutions had ‘gone through the roof’, especially following the events of the release of ChatGPT.
“The activity around the AI infrastructure that we built, and the activity around inferencing using Hopper and Ampere to influence Large Language Models has just gone through the roof in the last 60 days,” Huang said. “There’s no question that whatever our views are of this year as we enter the year has been fairly dramatically changed as a result of the last 60, 90 days.”
Jensen Huang, Nvidia FY23
The ‘last 60‘ days is a reference to the wide-spread adoption of ChatGPT. The statement above was consistent with Jensen’s remarks earlier during Q3 FY22 regarding H100 production and shipping.
“Nvidia is the only company in the World to produce and ship semi-custom Supercomputers in high volume” to Cloud Service Providers. “
The plan was to ship one ‘semi-custom Supercomputer/s’ to every major Cloud Service Provider in a quarter. The ‘semi-custom Supercomputer’ refers to solutions such as DGX that are based on A100 and H100s. Due to the scalable nature of the GPUs, they can be combined/stacked to achieve greater levels of computational ability.
The statement above is so far the only example where we can quantify the sales of AI-based solutions to the major Cloud Service Providers (CSPs).
According to Wikipedia, the EOS Supercomputer is built and owned by Nvidia. It comprises ’18 H100 based SuperPods, totaling 576 DGX H100 systems,’
Assuming a DGX H100 costs $200,000, the price of a ‘super computer’ similar to EOS could be around $115 million. This could be the sales Nvidia makes in the upcoming quarters by selling ‘supercomputers’ to AWS, Azure and GCP.
As we saw above, statements from Nvidia have been very consistent over the past 2 years about the rising demand for GPUs for AI-related purposes.
Insatiable demand building up from AI Start Ups
Do we see evidence of the rising demand from the other side – users of GPU-based AI solutions?
Stability AI CEO Emad Mostaque wrote on Twitter in January 2023.
“A year ago we had 32 A100s,”
Stability AI CEO Emad Mostaque
Currently Stability AI has ‘access’ to 5400 A100 GPUs. That is a 168x increase.
Open AI needed 10,000 Nvidia GPUs to train ChatGPT. It is now finding it hard to keep up with the Inference demand as the popularity of ChatGPT grows:
“But the system is now experiencing outages following an explosion in usage and numerous users concurrently inferencing the model, suggesting that this is clearly not enough capacity,” Arcuri wrote in a Jan. 16 note to investors”
Fierce Electronics
Going forward, the demand is expected to double.
TrendForce gauged that ChatGPT required around 20,000 units to process training data
Tom’s Hardware
Tom Goldstein, Associate professor at the University of Maryland, ran a ‘back of the envelope’ calculation and estimated the cost of running ChatGPT monthly was $3 million. This assumed $100k per day based on 10 million queries ( 1 million users averaging 10 queries per day).
Everyone’s favourite AI ‘What-If’ analysis
A thought experiment that has captured the analyst community goes like this – what happens if we incorporate ChatGPT into Search?
SemiAnalysis is the most quoted estimate on this subject. Based on assumptions clearly stated by them, it would cost Google $100 billion to ‘ham fist’ ChatGPT into Google’s existing search businesses.
Deploying current ChatGPT into every search done by Google would require 512,820.51 A100 HGX servers with a total of 4,102,568 A100 GPUs. The total cost of these servers and networking exceeds $100 billion of Capex alone, of which Nvidia would receive a large portion.
SemiAnalysis
The article indicates this is extremely unlikely but it gives us a vague idea of the massive opportunity size staring at Nvidia.
A similar exercise of incorporating ChatGPT into every Bing search means using 20,000 DGX systems (of A100 or H100s) resulting in $4 billion in costs for Microsoft. Satya Nadella will probably be happier with this arrangement as the subsequent market share gains offsets the costs.
For every one point of share gain in the search advertising market, it’s a $2 billion revenue opportunity for our advertising business.
Satya Nadella
It is obvious that Search will incorporate AI Models. The extent itself cannot be predicted. Maintaining speed and relevance in Search is paramount and all players will need to have the fastest chips to maintain parity.
State of AI Survey – 91% Companies plan to increase GPU capacity
The much anticipated annual State of AI Infrastructure survey from Run:ai is out and it confirms our suspicions that everyone is out to grab as much AI-based infra as possible.
Some results of the Survey are given below:
- “91% of Companies are planning to increase their GPU capacity or AI infrastructure in the next 12 months”
- “AI Infrastructure challenges have surpassed the data issue, with 54% of respondents claiming it’s now their biggest challenge”
Meta has hoarded the most A100s
The State of AI Survey 2023 reveals another interesting nugget – Meta has 21,400 A100 GPUs as of 20 Nov 2023. Excluding the major Cloud Service Providers (CSPs), this is the highest concentration of processing power for AI. It even exceeds Governments including EU!
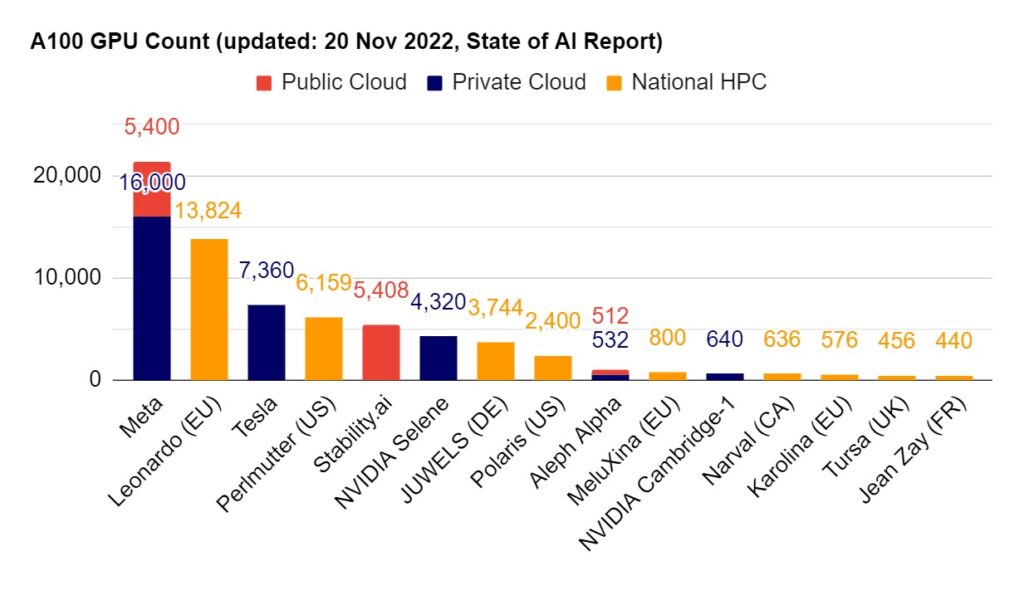
16,000 of these chips were ordered by Meta/Facebook in Jan 2022 for “building the world’s largest AI supercomputer to power machine-learning research that will bring the metaverse to life in the future” – the AI Research SuperCluster (RSC).
The RSC is 9x faster than the previous Meta Supercomputer, which had 22,000 of Nvidia’s older generation V100 GPUs.
This is another example of companies having to upgrade to faster GPUs just to keep up with the demands of AI or Metaverse or simply to remain competitive.
Tesla has significant GPUs of their own but is also quietly building them in-house
Tesla and Nvidia have had an interesting history, often collaborating but of late competing more than teaming up.
In 2016, Tesla dropped Mobileye Global Inc in favour of Nvidia as its vendor for Autonomous Driving solutions. (Mobileye was later acquired by Intel in 2017 and then spun off.)
The Nvidia-Tesla partnership ended in 2019 as Tesla designed its own ‘FSD Chip’ processors. Nvidia supplies the Drive solution to other players in the car market. Both companies are locked in a race to reach the pole position of the greatest prize in the auto industry – autonomous vehicles.
This collaboration-competition element is being played out again in the AI space. Tesla has 7360 chips of the A100 variety that power its current supercomputer. This is a 28% year-on-year increase from 5760 GPUs.
Tesla has a reputation for being vertically integrated and AI doesn’t seem to be any different. It is building another supercomputer called Dojo. What is interesting about Dojo is that it uses a ‘a custom chip’ called D1. This chip was developed in-house by Tesla. Tesla has claimed that it will be the fastest supercomputer when it is operational in FY23 and it doesn’t use any major Nvidia product/device!
This has been a trend seen earlier in the major Cloud Service Providers (CSPs) such as Google and AWS where they develop in-house abilities for AI Accelerators, but also use Nvidia GPUs for specific purposes. Others like Meta develop custom software such as Pytorch to make Nvidia’s GPUs work better with CPUs from other vendors (Intel and AMD).
Cited Chip Usage in AI Papers has grown 20x in 4 years
State of AI Report Compute Index report, which has sourced the data from Zeta Alpha, tracked usage of all Nvidia chips cited in open source AI papers.
Citations of A100 has exploded from 746 instances in 2021 to 3,329 in 2022. This represents a 346% increase in A100 chips, which are almost exclusively used in large data centers.
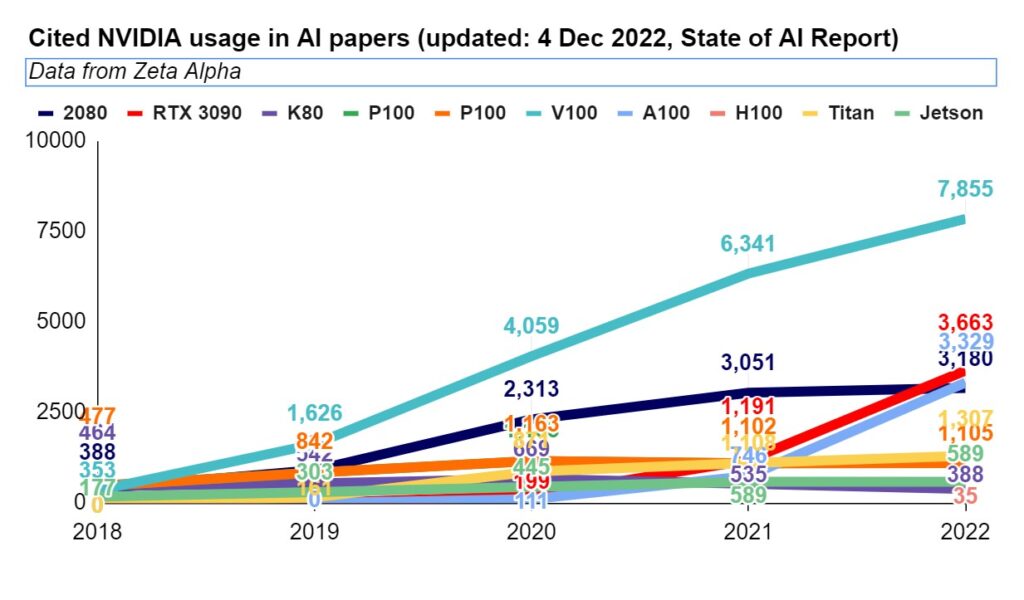
It would be hasty to draw conclusions from citations in open source AI papers but in the absence of specific data, we rely on these straws in the wind to gauge the longevity of the demand for Nvidia Accelerators.
VCs are throwing money at AI Start Ups but…
In Aug 2019, the AI start up Cerebras Systems shocked the Semi Conductor industry by unveiling the ‘biggest chip in the world’ – the Wafer Scale Engine (WSE).
One single WSE chip is the size of an entire Wafer – practically the size of a dinner plate! It is 56x bigger and around 50x faster than the A100.
In Aug 2022, Cerebras was honored by Computer History Museum for its gigantic achievement. Soon enough, the company also claimed to have trained the largest AI Model on a single ‘device’, the CS-2 which was built by combining the WSE chips together. In Nov 22, it unveiled its AI supercomputer called Andromeda, which was built by linking up 16 Cerebras CS-2 systems.
Cerebras was valued at $4 billion in 2022. Other start ups in this space have also been adequately funded; SambaNova ($5.1 billion) and Graphcore ($2.8 billion). Many of them reported similarly impressive achievements.
In Nov 2022, all eyes were eagerly awaiting MLPerf™ Training results. This is an industry benchmark for testing AI Hardware to determine the fastest ML Training and Inference performance. Given the giant leaps made by start ups (Cerebras, SambaNova and Graphcore) and industry veterans (AWS, GCP), was the end of Nvidia’s domination in sight?
Surprisingly not. Nvidia managed to sweep the show with the exception of Habana Gaudi2 from Intel-HabanaLabs. The Habana Gaudi2 won in a couple of rounds but in the other approximately 100 or so rounds, it was the Nvidia A100 that predictably ended up as the winner.
Note that the H100, which is 4-9x faster in Training AI Models than A100, wasn’t a part of the competition. This served as further proof of Nvidia’s superiority in AI field.
The ML Perf Benchmarks are sometimes criticized for not being wholly applicable in real-world scenarios or that the submissions can be ‘customised’ to perform better for the benchmarks. For now, the total domination of Nvidia means that it is still way ahead of its peers. And it is not resting on its laurels.
Another indication on whether the Accelerators (basically GPU chips) used by the start ups are gaining traction could be the instances of citations in AI papers. We used this approach earlier to get an idea of the YOY change in A100 demand.
Looking at the data below, it seems that the usage of chips developed by start ups is insignificant compared to Nvidia. For ex, Graphcore had 59 instances while all the various chips in Nvidia’s stable add up to 7,855 instances.
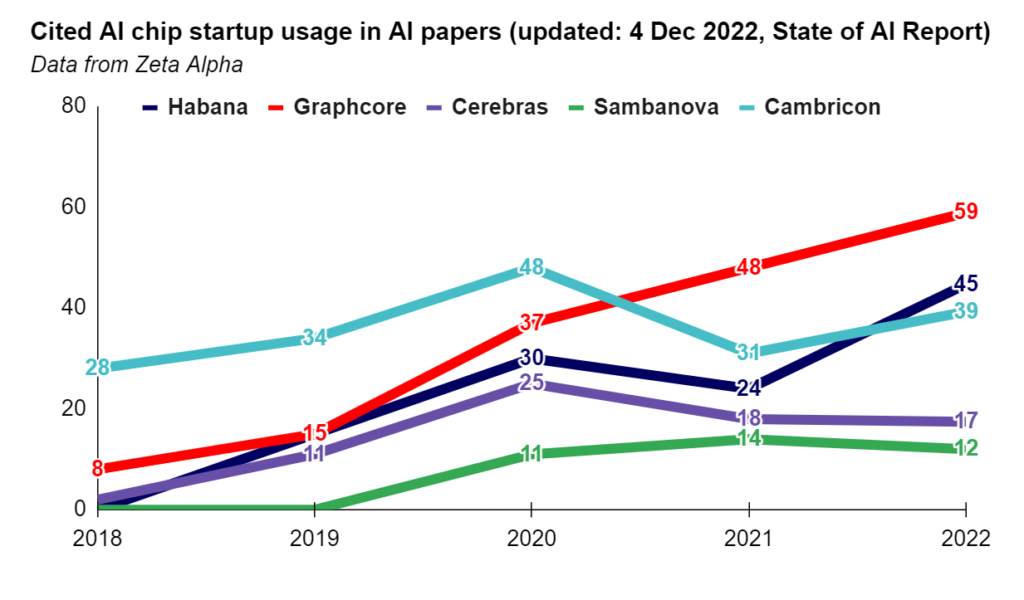
Conclusion
The buzz around AI is justified but hard to quantify. For now, we can rely on indications from Nvidia itself when it says that demand has ‘shot through the roof’ in a post-ChatGPT world.
We know that 40% of the Data Center revenue for Nvidia comes from the major CSPs (AWS, Azure, GCP). Nvidia has also declared its intention to ship one supercomputer to every CSP every quarter. This means a steady $115 million in revenues for the coming year or two.
Demand for LLMs such as ChatGPT and Stable Diffusion has exploded. This will benefit Nvidia in 2 ways – Training newer versions of LLMs and Inference at Data Centers (running the LLMs). For example, newer versions of ChatGPT will need twice as many GPUs reportedly.
Another big development is the integration of AI into software and search. We saw estimates of incorporation of ChatGPT into Google search by 1-2% will result in $1-2 billion additional revenues for Nvidia.
Microsoft has already demonstrated its intent of incorporating AI into its Office suite. Other software vendors are hurriedly coming up with their own versions of this AI incorporation. This market is hard to quantify but could be as big as Search for Nvidia. This is reflected in the State of AI Survey where 91% of Companies are planning to increase their GPU capacity.
The AI opportunity is too big and too enticing for others to watch idly. Traditional competitors like Intel are nowhere near the performance of Nvidia in GPUs. AMD is Nvidia’s closest rival for Data Center GPUs and has several competitive products. However, Nvidia’s software CUDA is the industry standard and this is proving to be a stumbling block for adoption of AMDs GPUs.
Established Tech giants like Meta and Tesla are working on developing their capabilities in-house. The same holds true for Amazon and Google. Several start ups are reimagining how chips can be designed. For now, they are nowhere close to Nvidia as can be seen in the results of the ML Perf Benchmarks or citations in Open Source AI. That said, all of Nvidia’s competitors are heavily funded and have the best talent at their disposal.
We know for sure that the coming quarters will see a tremendous increase in demand for Nvidia’s products in the AI space. Is this enough to justify Nvidia’s PE that is around 100? We will have to wait and see.
APPENDIX: References and Resources
- Nvidia’s A100 GPU sets new performance records in MLPerf benchmarks
- NVIDIA H100 80 GB PCIe Accelerator With Hopper GPU Is Priced Over $30,000 US In Japan
- Update: ChatGPT runs 10K Nvidia training GPUs with potential for thousands more
- ChatGPT Will Command More Than 30,000 Nvidia GPUs: Report
- 2023 STATE OF AI INFRASTRUCTURE
- Meta says it’s building world’s largest AI supercomputer out of Nvidia, AMD chips
- Tesla unveils new Dojo supercomputer so powerful it tripped the power grid
Thanks for another informative blog. Where else could I get that kind of info written in such a perfect way? I’ve a project that I’m just now working on, and I have been on the look out for such info.
Good blogs thanks
Tak skal du have!|Olá, creio que este é um excelente blogue. Tropecei nele;