In the first part ‘AI Scaling Laws and the Race to AGI – Part 1‘, we explored:
- Artificial General Intelligence (AGI) is the goal for most Artificial Intelligence (AI) companies.
- The 3 key factors that define a Large Language Model (LLM): Model Size (N), Training Dataset Size (D) and Training Cost (C).
- Training LLMs is GPU intensive – For ex, ChatGPT-4 was trained on 25,000 Nvidia A100 GPUs!
- An overview of ‘AI Scaling Laws‘ – These indicate that increasing the 3 key factors listed above (N, D or C) leads to an improvement in the LLM’s ‘quality.
In this blog, we will look at why AGI is an opportunity and an existential risk for most tech companies.
AGI – Opportunity or Existential risk for Big Tech?
In 2005, Ray Kurzweil predicted in his book ‘The Singularity Is Near’ that we would reach AGI by 2029. Not content in having spooked his audience, he went on to state that human and machine intelligence would merge to reach ‘the Singularity’ by 2045.
Ray defined AGI as:
“AI that can perform any cognitive task an educated human can”
The simple statement above has world-changing implications. The current generation of LLMs have already passed the Turing test with disconcertingly flying colors. The leap to AGI would mean AI can replace all types of human economic activity.
A) Replacing knowledge work – Autonomous AI Agents
As we saw in Part 1, GPT 4o passed exams for United States Medical Licensing Examination (USMLE) and Uniform Bar Exam (UBE). While LLMs can pass exams, there is no evidence yet that they can function as Doctors or Lawyers. That is why currently most LLMs are working as ‘Copilots’ and supporting employees with tasks/activities.
With AGI, the employment scene transforms. Instead of employees, you can have AI Models that can perform at par or higher than their human counterparts.
Further ahead on the tech stack, AI can be incorporated as companies that can function independent of human supervision.
B) Replacing physical work – Embodied Robots
The technological leaps we saw in AI from Nov 2022 onwards seemed at first to evade Robotics. The humanoid robots continued pottering around in their pre-ordained paths, taking measured steps. Devoid of intelligence, agility or dexterity, they seemed content to exist as placeholders for the future. Occasionally, Boston Robotics would blow our minds with the Atlas robots doing backflips. But the same back-flipping robot would not be able to do something as simple as sit on a chair.
That is now changing with Roboticists and AI scientists figuring out how to incorporate LLMS into robots, providing a much needed interface between humans and robots.
B) Replacing physical work > Nvidia – Pen-twirling robots
Nvidia caught our attention when Eureka, an AI agent, ‘trained a robotic hand to perform rapid pen-spinning tricks — for the first time as well as a human can’. Earlier generations of robots were one-trick ponies but Eureka taught robots ‘nearly 30 tasks that robots have learned to expertly accomplish’.
(Source – Nvidia)
So how do LLMs come into the picture?
The AI agent taps the GPT-4 LLM and generative AI to write software code that rewards robots for reinforcement learning. It doesn’t require task-specific prompting or predefined reward templates — and readily incorporates human feedback to modify its rewards for results more accurately aligned with a developer’s vision.
(Source – Nvidia)
(As an aside, Nvidia isn’t just an AI picks-and-shovels play. It owns an AI gold mine through a) NVIDIA AI Enterprise b) Robotics suite and c) Omniverse. Look out for an article on this coming soon).
B) Replacing physical work> Google – PaLM-SayCan
Nvidia’s Eureka showed that robots can be taught by virtual AI agents to perform complex physical activity. While the range of activities are complex, these are still pre-programmed activities.
In Aug 2022, Google’s PaLM-SayCan project showcased a robot that can understand a human being. For the first time, you can ask a robot to do something, it can understand what you asked and complete the task. In a real-world scenario.
(Source – CNET)
Google’s LLM model called PaLM helps the robot to understand conversational English. An impressive array of PaLM-SayCan capabilities is shown in this article from CNET.
B) Replacing physical work>Figure AI
Figure AI took the advances to its natural conclusion – a Robot that interacts with us. You can actually talk to a Robot now!
In the video, you will see the CEO of Figure AI talking to the Figure 01 Humanoid Robot. The conversation is important because:
- The Robot is able to show awareness/context through clear articulation.
- Is able to perform an action without explicit instructions. You dont need to say ‘Give me an apple’. Simply saying “I am hungry” was enough to prompt the robot to hand over an apple.
- Is able to deconstruct what it did and explain its actions.
The examples above show that it is possible at some point for AI to replace all human work – knowledge or physical.
Major Capex Announcements in 2024
In 2024, significant capex announcements were made by the largest companies in the world. Most of this capex will go towards buying Nvidia’s GPU-centric solutions.
- Meta Platforms: $8-10 billion deal with Nvidia to purchase 350,000 H100 GPUs by the end of 2024.
- Tesla: Plans to invest around $3-5 billion in Nvidia GPUs for AI training by the end of 2024.
- xAI: Announced a $10 billion investment in AI projects, including the construction of a supercluster called Colossus equipped with 100,000 liquid-cooled H100 GPUs.
- Microsoft: According to UBS analyst Timothy Arcuri, Microsoft was responsible for 19% Nvidia’s revenues in FY 2024. By 2024 year end, Microsoft plans to buy 1.8 million GPUs.
‘The State of AI Report 2024’ released on Oct 10, 2024 shows that Meta is already running clusters of 350k H100 GPUs, with Tesla and xAI as distant number #2 and 3.
Nvidia H100 Clusters (Source)
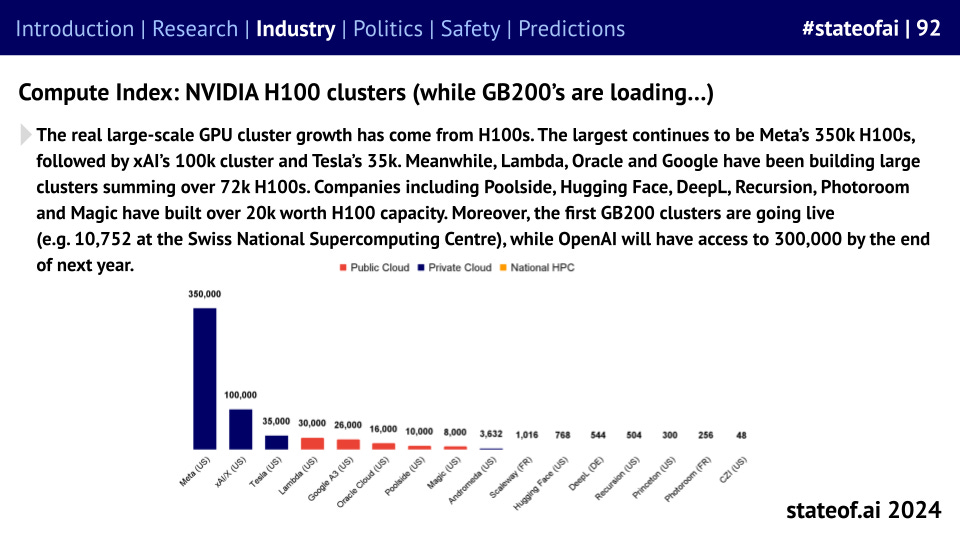
Even Google and Amazon, who have developed their own custom advanced AI Accelerators, have to stock up on Nvidia chips.
According to The Next Platform, Google has substantially more GPUs than its own custom-built Tensor Processing Units (TPUs). The TPUs are used for training Google’s AI initiatives (Gemini, PALM, Google Search/Youtube etc). The customers of Google Cloud Platform (GCP) however, need Nvidia GPUs as they are the best and flexible enough to handle general AI workloads (TPUs were developed specifically for Google’s requirements).
It is hard to say, but the Google GPU fleet is probably 2X to 3X the size of the TPU fleet…
The Next Platform
Another important reason why customers of Hyperscalers such as Google and Amazon need Nvidia chips is to access ‘Nvidia AI Enterprise software stack’. As we keep emphasizing, Nvidia just doesn’t sell pickaxes and shovels, it also owns a few AI gold mines.
Still, the TPU doesn’t support the Nvidia AI Enterprise software stack, and that is what a lot of the AI organizations in the world use to train models.
The Next Platform
Billion Dollar LLMs coming up
In Part 1, we quoted Anthropic CEO Dario Amodei who said that training LLMs could cost $10 -$100 billion over the next few years.
Google launched Gemini Ultra in Dec 2023, a premium offering that replaced the unlucky Google Bard. The cost was of training Gemini Ultra is around $191 million.
Open AI in the meantime is working on GPT 5. While GPT-4 cost around $100 million, GPT-5 is estimated to cost $1.25-2.5 billion!
The trend is clear. LLMs are scaling exponentially in all key aspects such as Model Size (N parameters), Training Dataset Size (gb/tokens) or Training Costs ($). Each generation is at least an ‘Order of Magnitude’ (min 10x) bigger than the previous generation in terms of training cost.
This explains why Dario Amodei believed that training costs of LLMs could be in the $10 – $100 billion range over the next few years. If GPT-6 were to be launched in a few years, we can assume it could cost around $12 – 24 billion. A GPT-7, which could launch as early as 2027, might need around $120 billion (10x of GPT-6 cost and 100x of GPT-5 training cost).
On 23 Sept 2024, Sam Altman of OpenAI speculated that AGI could be only a ‘few thousand days’ away. He raised eyebrows, even in Dubai, when he talked about a $7 trillion investment in AI hardware to reach ‘superintelligence’.
OpenAI CEO Sam Altman recently published a blog post highlighting that superintelligence might only be “a few thousand days away,” but it’ll “take $7 trillion and many years to build 36 semiconductor plants and additional data centers” to bring the vision to fruition.
Source
The rocky road ahead
The path to AGI is not easy. Respected voices in the AI research world such as Gary Marcus or Francois Chollet believe that the current LLM-centric approach may not be optimal.
Moving from the theoretical realm to the real world, we encounter an obvious hardware limitation – GPUs. In 3-4 years, for Nvidia to manufacture 100x more GPUs, the entire supply chain must rise to the challenge. TSMC needs to have adequate COWOS manufacturing capacity. HBM memory chipmakers such as Micron, SK Hynix, and Samsung are currently sold out till 2025 and will need to ramp up massively within 3-4 years. These are just two of the most obvious examples but hundreds and even thousands of companies will have to crank up production to meet the demands of AI hardware.
Electricity is another significant limitation. Hyperscalers are buying Nuclear Power Plants in anticipation of surging power needs. According to Goldman Sachs, ‘Data centers will use 8% of US power by 2030, compared with 3% in 2022.’
Conclusion
AGI is important for Big Tech because it is an existential risk. The Magnificent 7 is already 40% of NASDAQ and they have the most to lose. At stake is survival itself.
Google was the leader in AI. It started the current LLM revolution when it released the paper ‘Attention Is All You Need’ in 2017. For whatever reasons, it sat on its advantage until Microsoft and OpenAI gave it a real scare with ChatGPT and CoPilot announcements. For a while, it seemed that the most profitable business on earth (Google Search and Ads) could be disrupted by AI. Google’s hurried response and mis-steps saw it lose $100 billion in market cap in a single day when it launched Bard. Google did recover but it is no longer complacent about AI. This shows that no company, however dominant, is safe from being disintermediated or disrupted by AI.
LLMs showed that even high-end jobs could be made redundant via technology. The incorporation of LLMs into Robotics has demonstrated that no physical job is beyond the reach of technology. AGI is where the AI magic will finally happen. It is also an opportunity for Big Tech to continue its growth path, well beyond the gravity of trillion dollar market cap that the Magnificent 7 have reached.
The final part will examine the limits of AI Scaling and predictions from experts on when AGI will manifest itself.
Disclaimer: The information provided on this blog is for general informational purposes only and should not be construed as professional financial advice. The author(s) of this blog may hold positions in the securities mentioned. Past performance is not indicative of future results. The author(s) make no representations as to the accuracy, completeness, suitability, or validity of any information on this site and will not be liable for any errors, omissions, or any losses, injuries, or damages arising from its display or use.
By using this blog, you agree to the terms of this disclaimer and assume full responsibility for any actions taken based on the information provided herein.